Welcome
Complex Systems and Humanities at the University of Georgia
Director: Bill Kretzschmar, Harry and Jane Willson Professor in Humanities, Department of English
This site is dedicated to promoting the study of Complex Systems.
Affiliated projects and programs at UGA include the Willson Center, The English Department, and the DigiLab at UGA Libraries.
Description
A complex system is a system in which large networks of components with no central control and simple rules of operation give rise to complex collective behavior, sophisticated information processing, and adaptation via learning or evolution. Complexity science has proven useful in research on evolutionary biology, quantum physics, ecology, among others. An ant hill is a complex system, and so is the human immune system. Human culture is also a complex system: people interact, share information, and cultural patterns emerge as a result of feedback in the system. An economic market is a human complex system, and so is human language. The order that emerges in human language is simply the configuration of components, whether particular words, pronunciations, or constructions, that comes to occur in our communities and occasions for speech and writing.
Cellular Automaton
Density Maps
Point Pattern Charts
Resources
There are many different resources available at this site with regards to Complex Systems and the Humanities at UGA.
The articles include information about different aspects of complex systems and other topics associated with interdisciplinary work and complexity. Check it all out here!! Affiliated projects are available at the other tabs, including LAP, DASS, and the Cellular Automaton.
What is a Complex System?
A Complex System is a system in which large networks of components with no central control and simple rules of operation give rise to complex collective behavior, sophisticated information processing, and adaptation via learning or evolution.

A complex system is characterized by the activity of many different components, which leads to the reinforcement of behavior in the system. Through the interaction of components in a complex system, dynamic activity occurs and yields to reinforcement of behavior. This ultimately creates the patterns that are characteristic of a complex system and shown above in the blood vessels within the eye. Here we see activity and reinforcement of all the components involved in the complex system of the retina and the human eye. Other examples include economic activity leading to certain market patterns, fractal patterns found in certain natural occurrences like coastlines and trees.
Complex systems are all characterized by the involvement of many components.

A complex system is characterized by the involvement of many different components, all of which depend on the system. The components within give way to complex behavior, and this behavior cannot be exactly predicted. The system depicted above is of the many elements involved in the spread of information through the internet, which is also a complex system. Another example includes linguistic behavior which gives way to certain patterns, but without any people using specific instances of language, the language itself becomes obsolete.

Emergence is a key, underlying trait of a complex system. Emergence is what happens from the activity using all components in the system and creates complex patterns and behavior.
Emergence is a key characteristic of complexity and describes the result of interaction within the system. It occurs in all complex systems, whether inside the human body, in economic processes, or in nature, as shown in the fractal patterns of the leaf. Emergence leads to the creation of stable patterns, such as continued usage of certain items in language, leading to linguistic change.
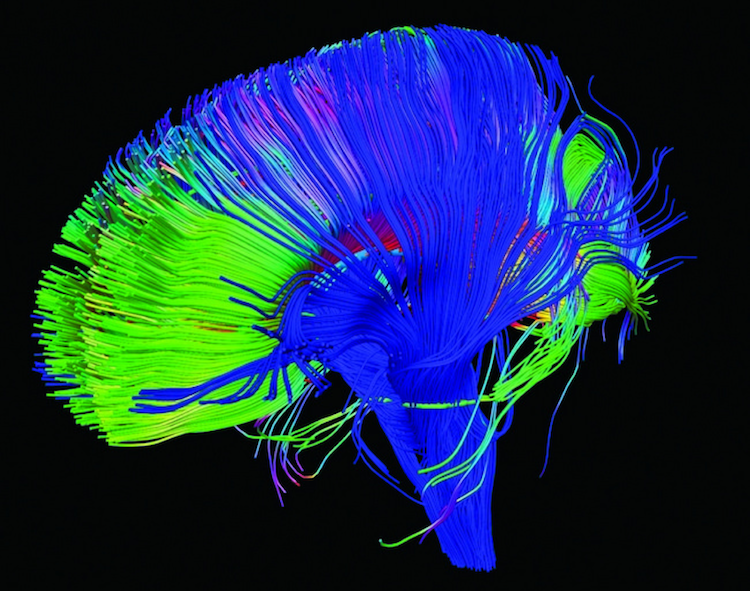
A complex system is also characterized by the exchange of information.
Many complex systems are involved in the exchange of information in the brain. Neurons, synapses, and receptors are all reacting to information inside and outside the body.